| Doctor Stat |
Статистический анализ
- Описательная статистика по одному параметру
- Регрессионный анализ
- Дисперсионный анализ
- Хи-квадрат и Фишер
1.Описательная статистика по одному параметру
Пусть нас интересует среднее значение, дисперсия или др. характеристики какого-либо количественного параметра в выборке. Открываем учебную базу данных. Как это делать описано в разделе Начало работы с учебной базой данных. В окне Выборки выбираем любую выборку, например Возраст9-22, соответсвующую всем пациентам в возрасте от 9 до 22 лет. Проверяем, что в правом верхнем окне Условия галка сброшена. Это нужно для того, чтобы в окне Параметры выводились параметры базы данных, а не условия. В окне Параметры выбираем любой числовой параметр, данные по которому есть в базе, например, Возраст. Нажимаем кнопку Выполнить Запрос. Загружается Excel и на Лист1 выводится столбец возрастов всех пациентов. Переходим в Excel и нажимаем кнопку Макрос или комбинацию клавиш Ctrl+M, см.рис.1.
Рис.1 Кнопка запуска макроса.
В версии 2007 нужно перейти на последнюю вкладку Add-Ins и нажать кнопку Макрос, см.рис.1.0.
Рис.1.0 Кнопка запуска макроса в Excel 2007.
1.1 Особенности запуска Макроса в русской версии Excel 2007
В русской версии 2007 есть одна "кривизна", осложняющая жизнь и мешающая непосредственному запуску макроса. После вывода в Excel данных перед запуском макроса нужно один раз проделать следующую процедуру. Переходим на вкладку Данные, нажимаем кнопку Анализ данных. Появляется окно Анализ данных, в котором нажимаем кнопку Отмена, см.рис.1а.
Рис.1а Перед запуском макроса в Excel 2007.
Теперь запускаем макрос с помощью кнопки или комбинации клавиш.Запускается макрос, который на лист Гистограмма выводит таблицу и гистограмму возрастов, см.рис.2
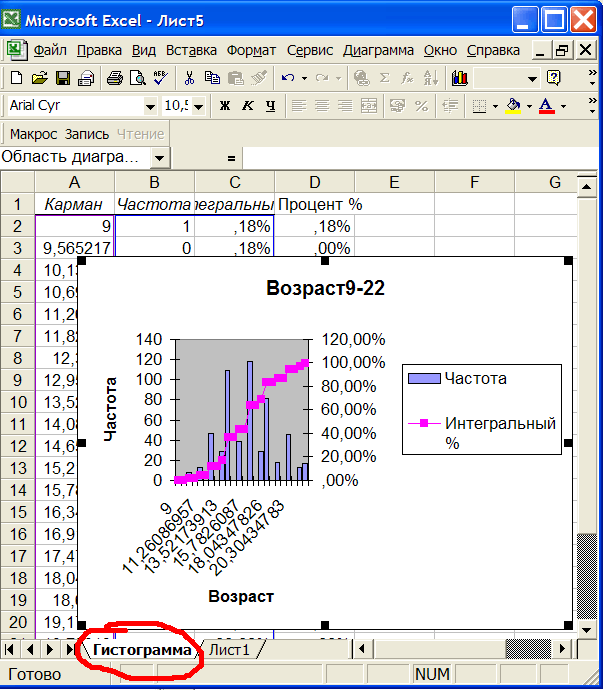
Рис.2 Гистограмма возрастов в выборке.
Из гистограммы видно, что распределение людей по возрасту приблизительно нормально: в центре максимум, а к краям постепенное уменьшение. На Лист1 выводятся стандартные статистические показатели: среднее, стандартная ошибка, медиана и т.д., см.рис.3
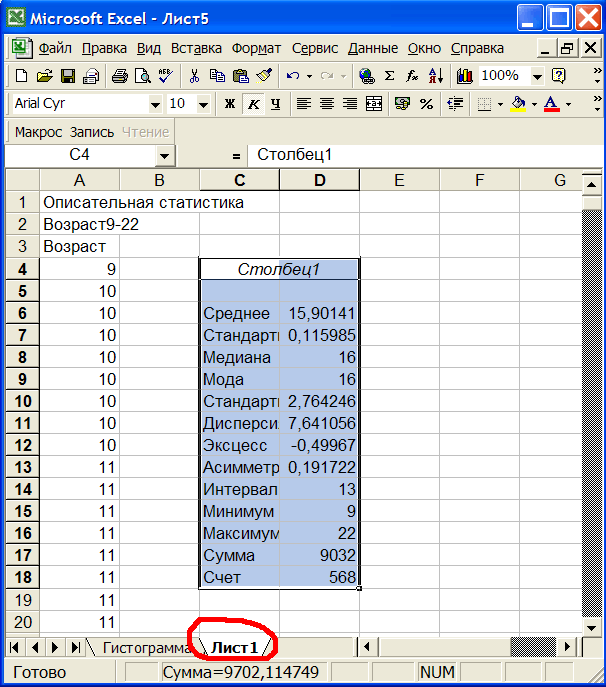
Рис.3 Статистические показатели выборки.
Из рис.3 видно, что средний возраст в выборке равен 15,9 лет.
2.Регрессионный анализ
Пусть нас интересует зависимость одного количественного параметра от другого для данной выборки. Используем регрессионнй анализ. Создадим условие Пол=0, которое соответствует женщинам. Комбинируя условия муж ИЛИ жен, создадим выборку всябаза. Вся, потому что каждый пациент является мужчиной ИЛИ женщиной. Тестируя выборку, увидим, что в ней 1209 человек. Для небольшой части пациентов в базе есть данные по гемоглобину и эритроцитам. Проверим с помощью регрессионного анализа, связаны ли эти два количественных показателя. Для этого выделим мышью в окне Выборки выборку всябаза, а в окне Параметры, удерживая нажатой клавишу Ctrl или Shift, параметры гемоглобин и эритроциты. Мы хотим получить зависимость гемоглобина от эритроцитов, поэтому первым выделяем гемоглобин. Нажмем кнопку Регрессия или выберем в меню: Анализ->Регрессия, см.рис.4.
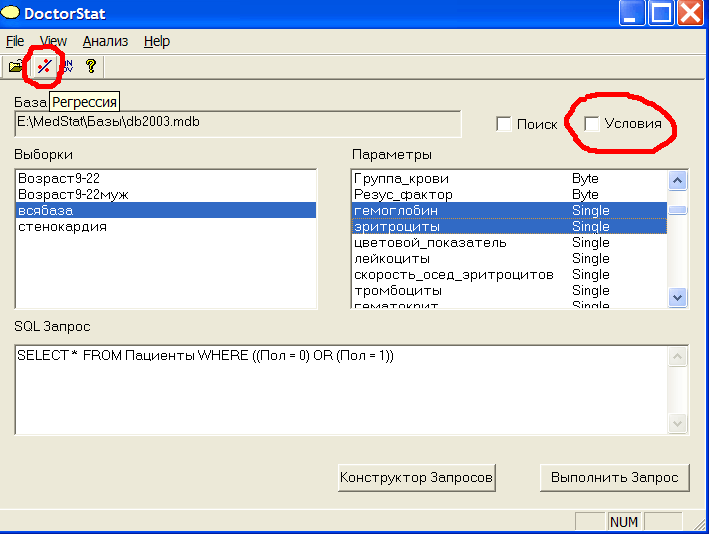
Рис.4 Выполнение регрессионного анализа.
В Excel появится новый Лист1. В первом столбце выведена зависимая переменная - гемоглобин, во втором независимая - эритроциты. Название выборки выводится во 2-ой строке. Количество пациентов 25, у которых заданы оба параметра, показано в ячейке В1, см.рис.5
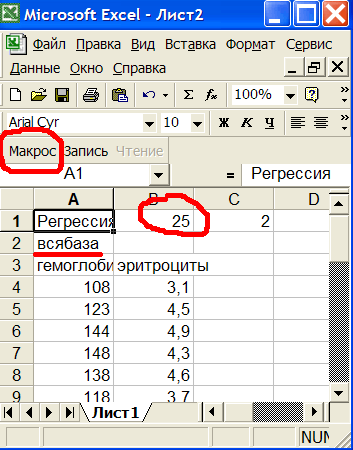
Рис.5 Вывод данных в Excel.
Нажимаем кнопку Макрос. На тот же лист выводятся результаты регрессионного анализа, см.рис.6
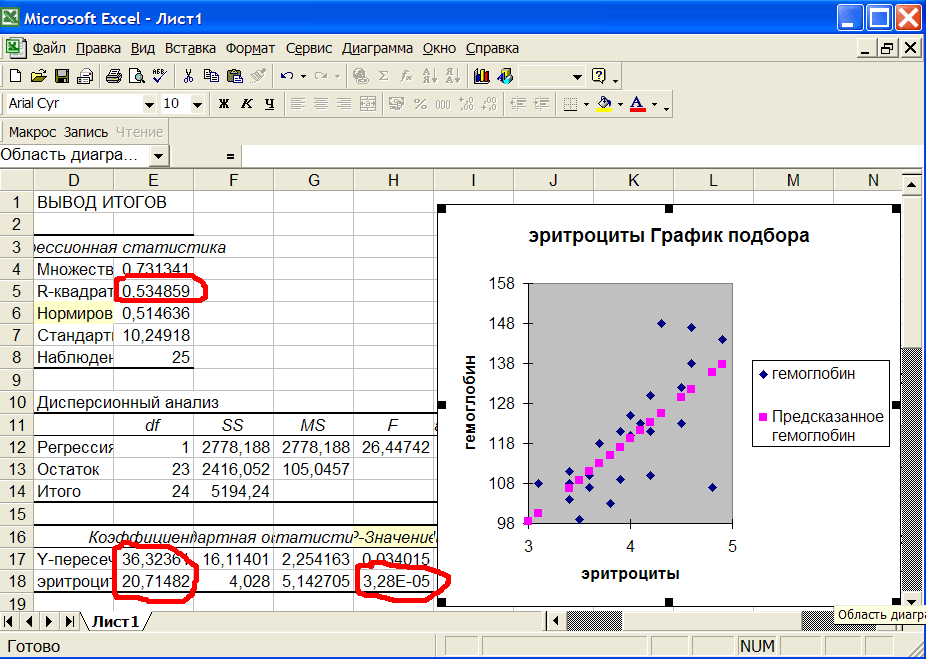
Рис.6 Результаты регрессионного анализа.
Смотрим на значимость линейной регрессии - Р-значение = 3,28Е-5 (ячейка H18). Это число много меньше 0,05, следовательно, зависимость гемоглобина от эритроцитов высоко значима. R-квадрат=0,534859 (ячейка E5) показывает какую часть изменчивости гемоглобина можно объяснить с помощью изменения эритроцитов. На графике видно, что наклон c2 прямой регрессии (розовый цвет):
гемоглобин = с1 + с2*эритроциты
положителен, т.е. с увеличением эритроцитов гемоглобин также увеличивается.
Коэффициенты прямой регрессии равны: с1=36,32361 (ячейка E17); с2=20,71482 (ячейка E18). Интерпретация с2: при увеличении эритроцитов на 1 гемоглобин увеличится на 20,7.
2.1 Множественный регрессионный анализ
Зададимся вопросом: какие еще факторы влияют на гемоглобин? Добавим к эритроцитам еще одну независимую переменную - лейкоциты и посмотрим, насколько она влияет на гемоглобин. Выделим в окне Выборки строку всябаза. Выберем в окне Параметры с клавишей Ctrl три параметра, соблюдая очередность: гемоглобин, эритроциты, лейкоциты. Нажмем вверху кнопку Регрессия. Переходим в Excel и нажимаем кнопку Макрос. На Лист1 выводятся результаты множественной регрессии, см.рис.7
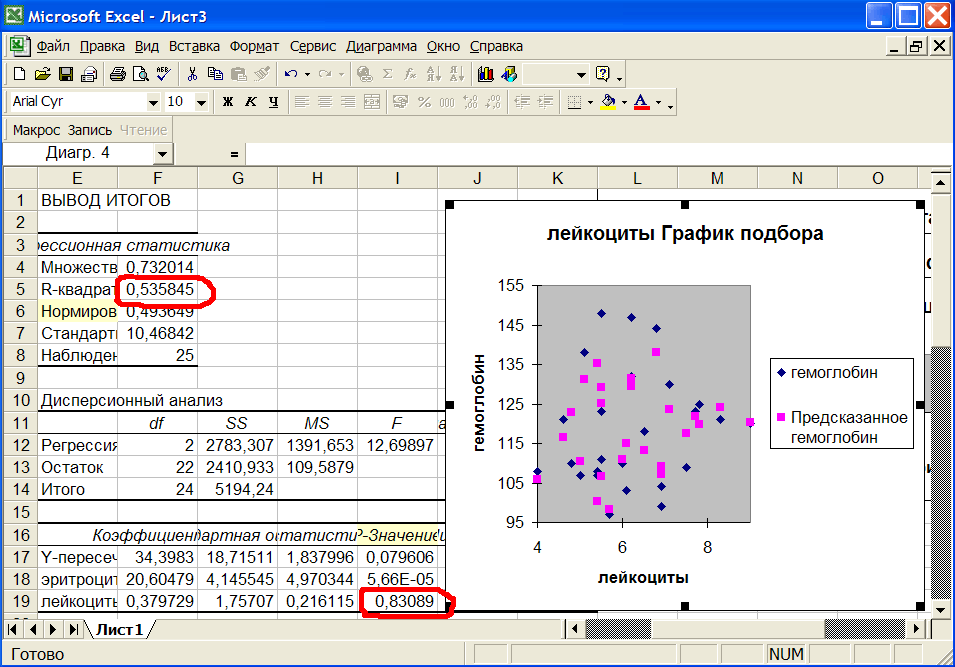
Рис.7 Результаты множественного регрессионного анализа.
Смотрим Р-значение для лейкоцитов = 0,8389 (ячейка I19). Оно много больше 0,05. Следовательно, лейкоциты не влияют на гемоглобин. График справа подтверждает вывод - не видно никакой структуры в облаке точек. Коэффициент R-квадрат (ячейка F5) также подтверждает наш вывод - он вырос очень незначительно: с 0,535 до 0,536.
2.2 Сравнение линий регрессии
Сравним для 2-х выборок: муж и жен линии зависимости гемоглобина от эритроцитов. Выбираем в окне Выборки с клавишей Ctrl две выборки жен и муж. В окне Параметры выбираем два параметра (соблюдать очередность!) гемоглобин и эритроциты. Нажимаем кнопку вверху Регрессия с изображением прямой, см.рис.7а.
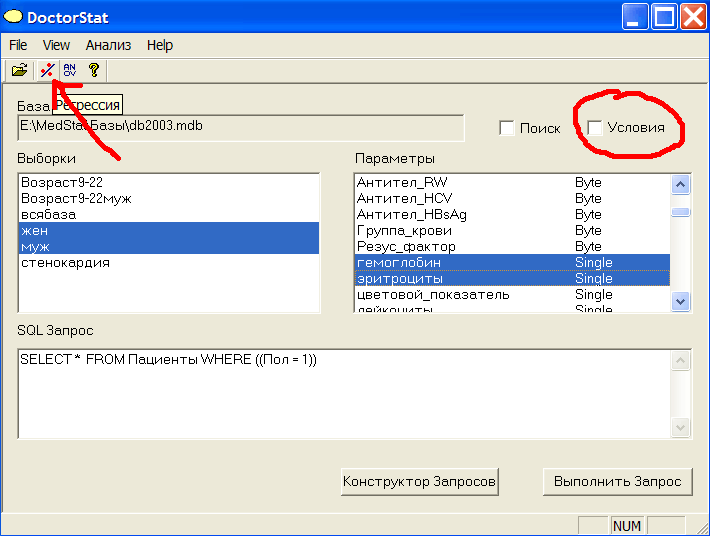
Рис.7а Сравнение линий регрессии для мужчин и женщин.
В Excel выведутся значения параметров для 2-х выборок. Переходим в Excel и нажимаем клавишу Макрос. На Лист1 выведется таблица сравнения коэффициентов регрессии, см.рис.7б
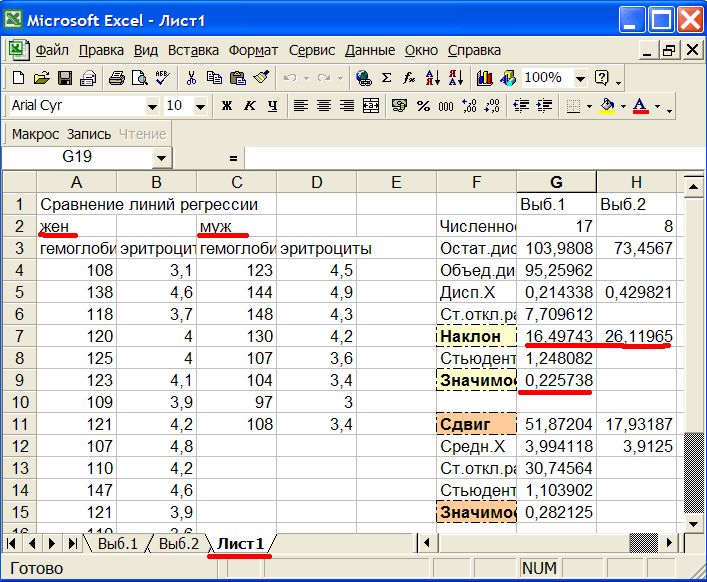
Рис.7б Результаты сравнения линий регрессии.
Из рис.7б видно, что хотя наклоны прямых для мужчин и женщин существенно отличаются: 16,49743(ячейка G7) и 26,11965(ячейка H7), тест не выявил различий Значимость=0.225738(ячейка G9) много больше 0,05. Этот на первый взгляд парадоксальный результат можно объяснить малым объемом выборок. На двух других листах: Выб.1 и Выб.2 выведены результаты регрессионного анализа для каждой выборки.
3.Дисперсионный анализ
Зададим себе вопрос: отличаются ли две или более групп по какому-либо количественному параметру. Например, отличаются ли мужчины от женщин по гемоглобину? Сконструируем две выборки - муж и жен. Выберем с клавишей Ctrl эти выборки в окне Выборки. В окне Параметры выберем гемоглобин. Нажмем кнопку ANOV вверху или выберем в меню Анализ->Дисп.Анализ, см.рис.8
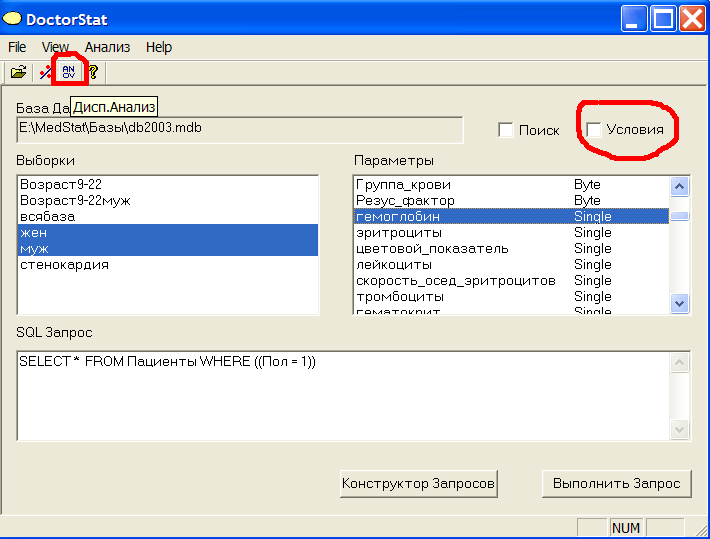
Рис.8 Выполнить дисперсионный анализ.
В Excel появится новый лист с гемоглобином в группе жен и муж. Количество мужчин (2-ой столбец), для которых задан гемоглобин, меньше количества женщин (1-ый столбец). В ячейке С2 выведен результат (P-value) непараметрического теста Крускала-Уоллиса. Видно, что значимость P-value=0.976763 много больше 0,05. Следовательно мужчины и женщины не отличаются по гемоглобину, см.рис.9.
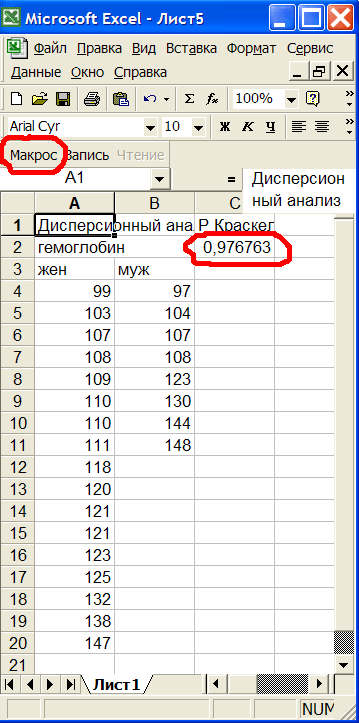
Рис.9 Непараметрический дисперсионный анализ.
Проверим этот вывод с помощью параметрического теста - нажмем кнопку Макрос. В результате будет выведена таблица однофакторного дисперсионного анализа, см.рис.10
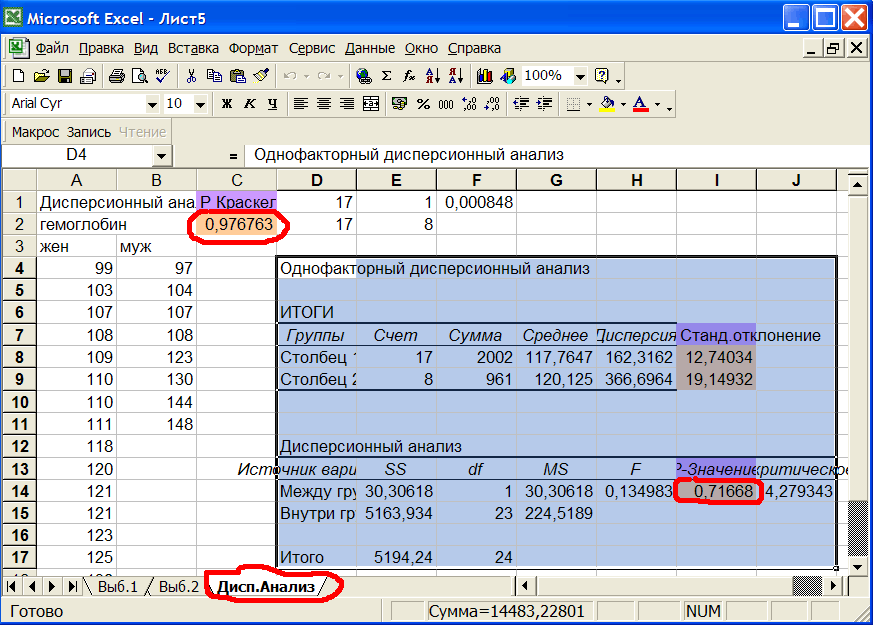
Рис.10 Результаты дисперсионного анализа.
В ячейке I14 дано значение P-value=0,71668 параметрического теста. Оно также много больше 0,05. На листе Выб.1 построена гистограмма гемоглобина для женщин, см.рис.11
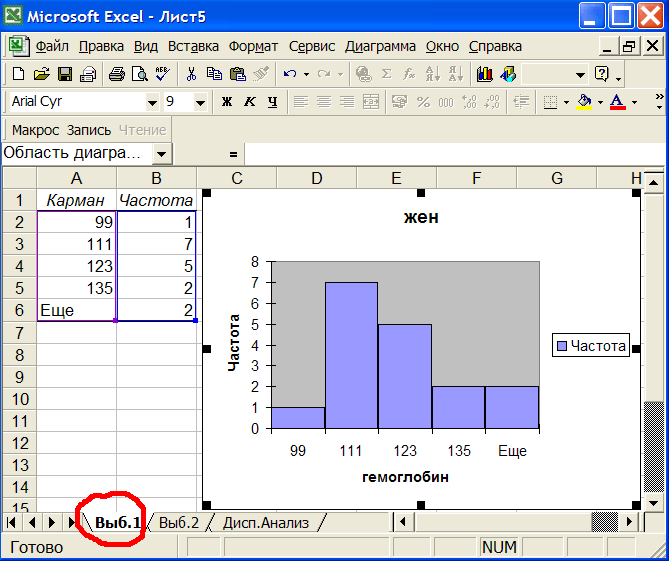
Рис.11 Гемоглобин в женской группе.
Из рис.11 видно, что распределение имеет форму колокола, т.е. приблизительно нормально. На листе Выб.2 показан гемоглобин для мужчин, см.рис.12
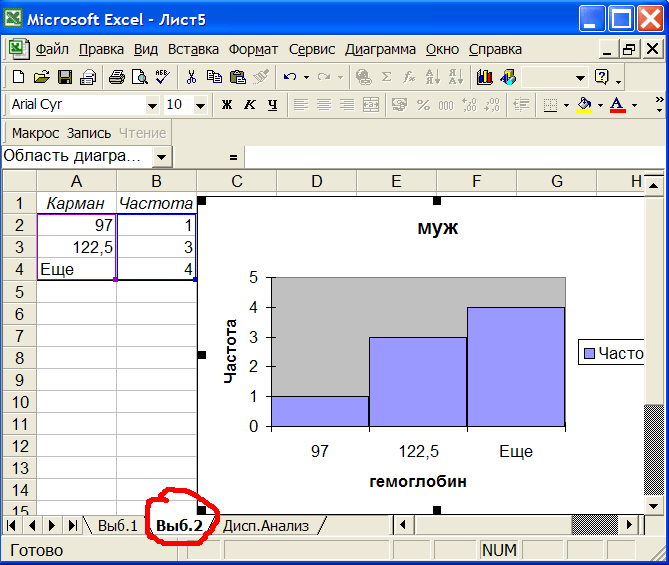
Рис.12 Гемоглобин в мужской группе.
Из рис.12 видно, что частота увеличивается с увеличением гемоглобина, поэтому распределение отлично от нормального. Следовательно, мы не можем использовать результаты параметрического анализа.
3.1 Сравнение эффективностей различных способов лечения
Вы только что закончили аспирантуру и поступили на работу в больницу. Вам дали отделение, где лежат женщины в возрасте от 40 до 50 лет со стенокардией. В этой больнице стенокардию принято лечить старым дедовским способом, а Вы слышали, что на Западе ее давно лечат более современными методами. Но как доказать руководству больницы, что новый способ лучше? В аспирантуре читали курс про доказательную медицину, которая опирается на статистику. Ну что же, попробуем применить наши знания на практике! Всего в отделении 20 больных. Случайным образом разобъем эту группу на 2 подгруппы по 10 человек в каждой. Первую группу будем лечить по старинке, а вторую новым способом. Качество лечения будем оценивать по количеству обращений к врачу за год (количество обострений болезни). В результате лечения оно должно уменьшиться. Уменьшение числа обострений мы сохранили в формуле РазностьОбращений. С помощью конструктора запросов создадим 2 выборки:- Возраст= от 40 до 50 лет, Пол=женщины (0), Лечение=1 (старый способ) и диагноз=стенокардия,
- все тоже самое, только Лечение=2 (новый способ)
Проверим, как часто посещали врачей больные 1-ой группы ДО лечения. Для этого выделим 1-ую группу в окне Выборки. В окне Параметры выделим ОбращенийДоЛечения и нажмем кнопку Выполнить Запрос, см.рис.12.0:
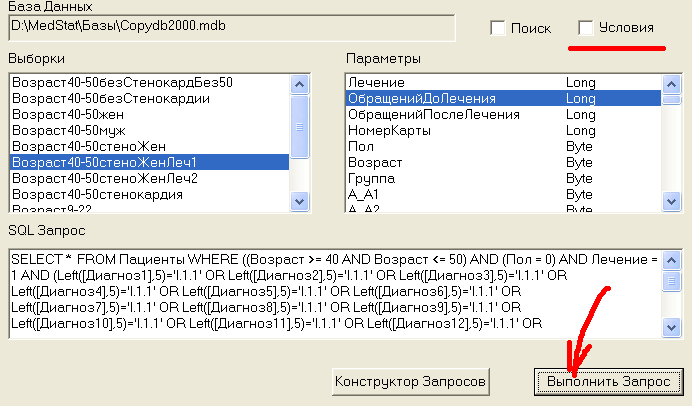
Рис.12.0 Описательная статистика по частоте обращений для группы 1.
После автоматической загрузки Excel перейдем в него и нажмем кнопку Макрос для вывода Описательной статистики по частоте обращений к врачу в 1-ой группе, см.рис.12.1:
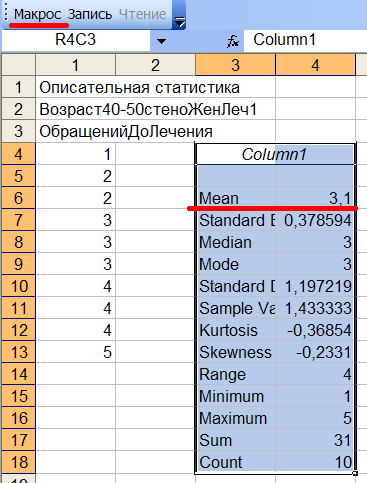
Рис.12.1 Результаты статистики.
Из 1-ого столбца рис.12.1 видно, что один больной обращался к врачу раз в год, двое по 2 раза, трое по 3 раза, трое по 4, один 5 раз. Среднее количество обращений до лечения в 1-ой группе равно 3,1 (Строка Mean в таблице справа).
Посмотрим, насколько снизилось после лечения количество обращений к врачу у группы, леченой 1-ым способом. Для этого в окне Выборки выделяем 1-ую группу, а в окне Параметры формулу РазностьОбращений и нажимаем кнопку Выполнить Запрос, см.рис.12а:
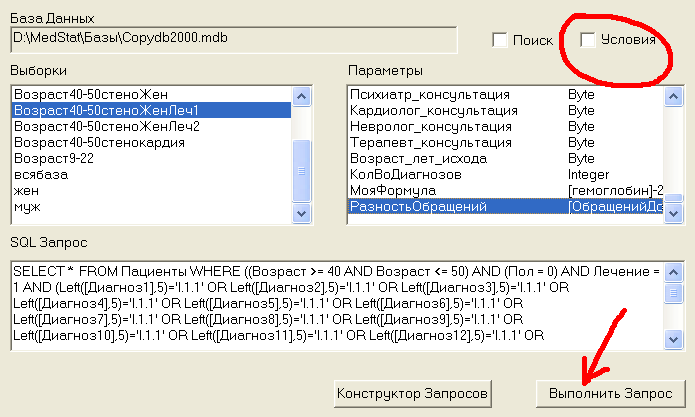
Рис.12а Описательная статистика для группы 1.
В Excel появляется новый лист с разностями обращений для каждого больного, см.рис.12б: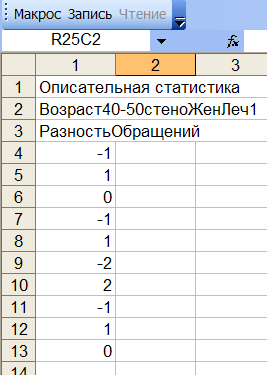
Рис.12б Разности обращений к врачу для группы 1.
У 4-х больных разность отрицательна, т.е. после курса лечения они стали ходить к врачу чаще. У 4-х разность положительна, у 2-х равна 0. Нажмем кнопку Макрос, чтобы вычислить Описательную статистику, см.рис.12в: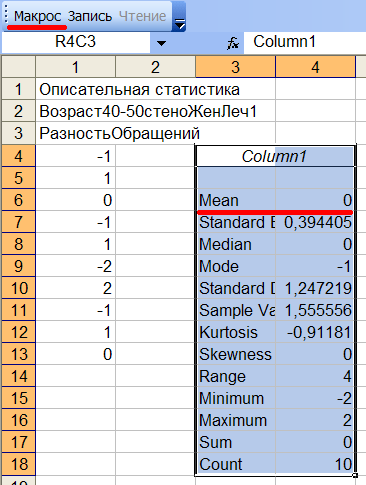
Рис.12в Среднее значение разности для группы 1.
Из рис.12в видно, что среднее значение разности обращений к врачу ДО и ПОСЛЕ лечения для группы 1 равно 0. Похоже, что старый способ лечения не эффективен! Теперь проделаем тоже самое для 2-ой группы, см.рис.12г: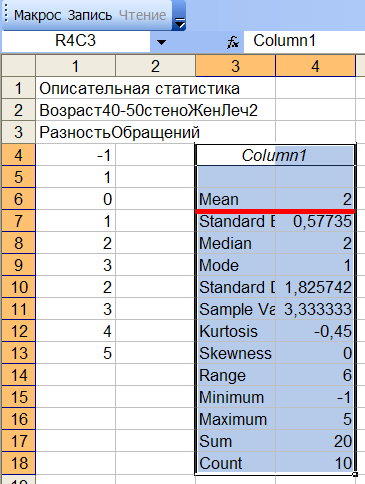
Рис.12г Описательная статистика для группы 2.
Из рис.12г видно, что только один больной после лечения стал чаще обращаться к врачу. У одного разность равна 0. У оставшихся 8 больных количество обращений уменьшилось (разность положительна). Среднее уменьшение количества обращений для группы равно 2 (Mean), что больше, чем у группы 1. Похоже мы на верном пути, и новый способ лечения более эффективен, чем старый! А что, если это уменьшение обусловлено случайностью, а на самом деле никакой разницы в изменении количества обращений нет? Так что же делать?! Ага, кажется нам рассказывали про дисперсионный анализ и его непараметрический аналог - критерий Крускала-Уоллиса. Попробуем их применить! Выделяем две сравниваемые группы в окне Выборки, выделяем формулу РазностьОбращений в окне Параметры и нажимаем кнопку ANOV, см.рис.12д: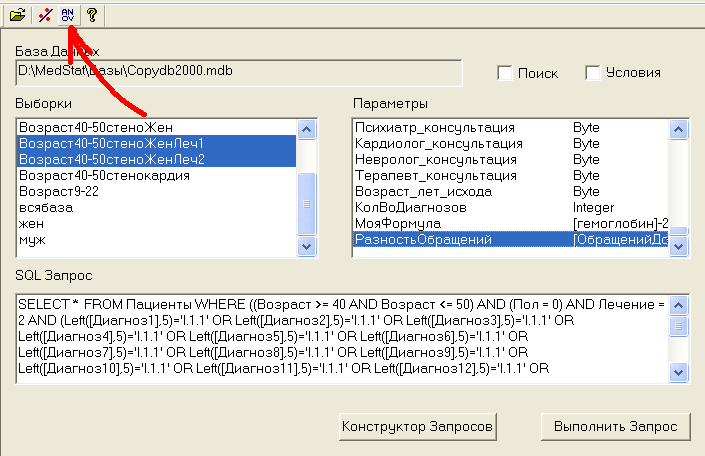
Рис.12д Сравнение разностей обращений к врачу для 2-х групп.
Переходим в окно Excel и нажимаем кнопку Макрос. На лист "Дисп.Анализ" выводятся результаты дисперсионного анализа и теста Крускала-Уоллиса, см.рис12е: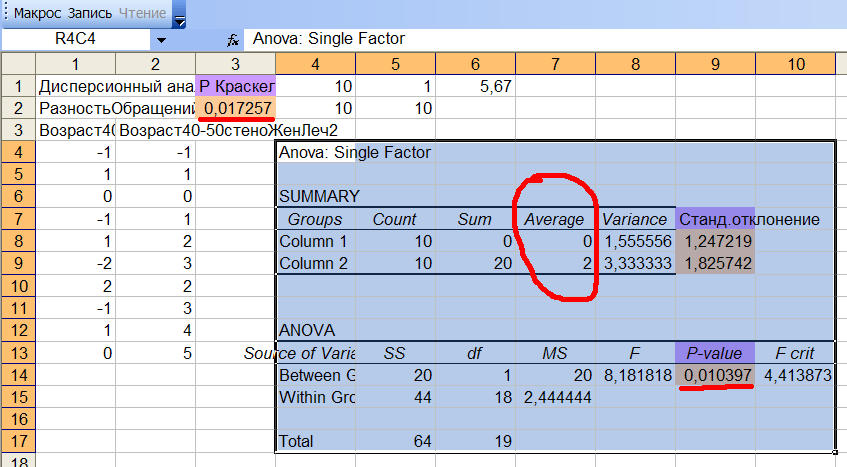
Рис.12е Результаты анализа разностей обращений для 2-х групп.
Из рис.12е видно, что среднее изменение количества обращений к врачу для групп 1 и 2 статистически различно. Значимость различий дисперсионного анализа равна P-value=0,010397, Крускала-Уоллиса 0,017257. Оба теста показали высокую значимость отличий. Но какой из 2-х результатов анализа выбрать: параметрический или нет? Так как мы не проводили проверку выборок на нормальность и равенство дисперсий, то лучше приводить результат непараметрического теста Крускала-Уоллиса.Вывод: снижение частоты обращений к врачу во 2-ой группе в среднем на 2 посещения больше, чем в 1-ой группе с уровнем значимости 0,02. Теперь с этими результатами уже можно идти к главврачу, чтобы в больнице наконец-то стали использовать правильный метод лечения больных!
4.Хи-квадрат и Фишер
Мы хотим знать отличается ли частота стенокардии для мужчин и женщин в возрастной группе 40-50 лет? Конструируем условие Возраст40-50, на основании которого создаем две выборки Возраст40-50муж и Возраст40-50жен. Тестируя выборки, видим, что объемы равны 59 и 211 человек соответственно. Вычисляя долю больных стенокардией, видим, что у мужчин она равна 8,5%, а у женщин 9,5%. Чем обусловлено отличие в 1%? Действительно ли женщины чаще подвержены стенокардии или это обусловлено случайностью выборки? Проверим эти гипотезы с помощью критериев хи-квадрат и Фишера. На основе условия стенокардия создаем его отрицание, т.е. будем выбирать пациентов, у которых в диагнозах нет стенокардии. Для этого нажимаем клавишу Конструктор Запросов. Выбираем Условия. Нажимаем кнопку НЕ (отрицание). В правом нижнем окне под названием Условия из базы выбираем стенокардия. Набираем в окне Описание запроса название условия, под которым оно сохранится в базе. Я ввел БезСтенокардии. Ставим галку в окне Сохранить. Нажимаем кнопку ОК, см.рис.13.
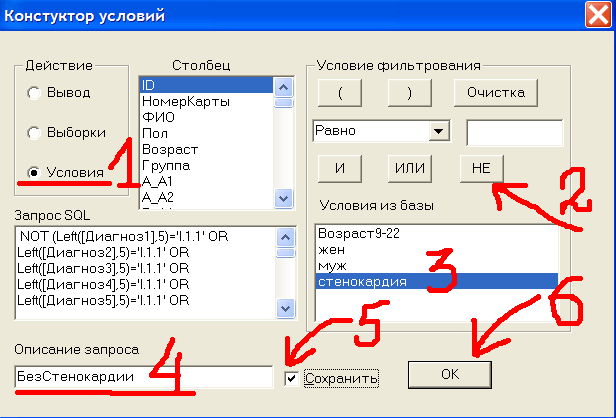
Рис.13 Отрицание условия с помощью кнопки НЕ.
Теперь условие БезСтенокардии попало в базу. У нас все готово для проведения хи-квадрат анализа: есть выборки и условия. Выделим с клавишей Ctrl в левом окне сравниваемые выборки, а в правом окне - условия и нажмем кнопку Выполнить Запрос, см.рис.14
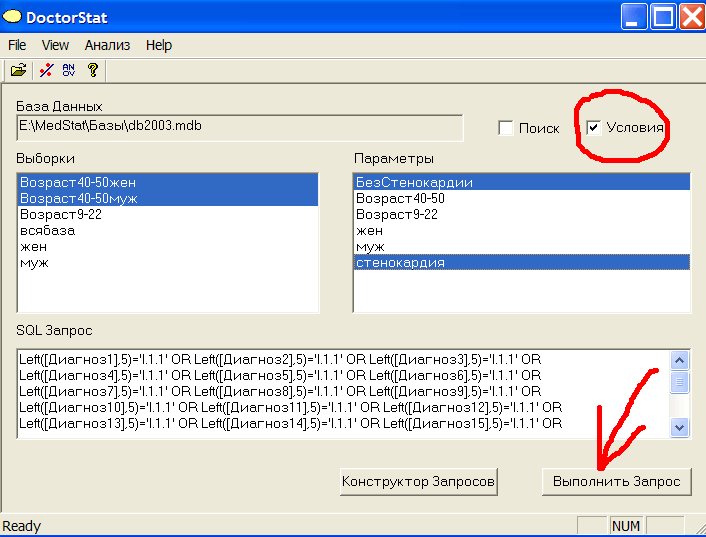
Рис.14 Выполнение хи-квадрат теста.
В результате в Excel будут выведены результаты 2-х тестов: хи-квадрат и 2-х стороннего Фишера, см.рис.15
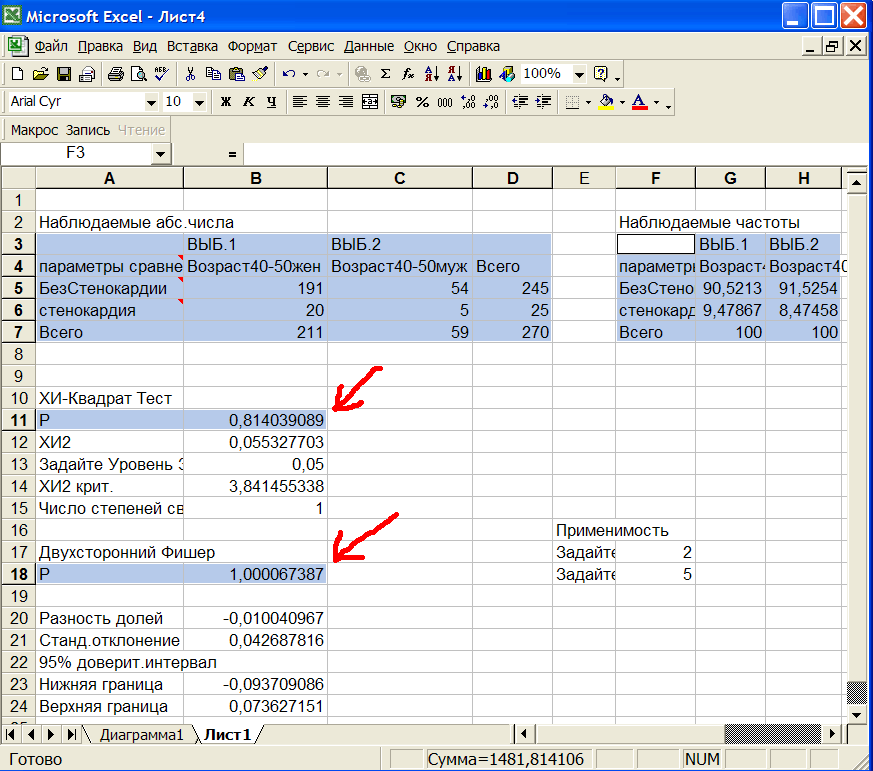
Рис.15 Результаты хи-квадрат и Фишера.
В таблице слева вверху "Наблюдаемые абс.числа" выведены количества пациентов. Видно, что объемы выборок равны 211(ячейка B7) и 59(ячейка C7) и совпадают с ранее вычисленными. Число женщин и мужчин со стенокардией равно 20 и 5 соответственно. В таблице справа вверху "Наблюдаемые частоты" мы видим, что частота стенокардии в группе женщин 9,47867%(ячейка G6), в группе мужчин 8,47458%(ячейка H6). Результат хи-квадрат теста (без поправки Иэйтса на непрерывность): p-value=0,814(ячейка B11), значение хи-квадрат=0,05532(ячейка B12). Результат 2-х стороннего Фишера p-value=1,000. Оба теста не нашли различий в частоте заболеваемости стенокардией у мужчин и женщин в возрасте 40-50 лет, т.к. обе величины p-value > 0,05. Таким образом различие в частоте заболеваемости обусловлено случайностью выборок.
На листе Диаграмма1 показана гистограмма наблюдаемых частот 2-х условий - БЕЗ стенокардии(слева) и СО стенокардией(справа) в 2-х выборках (сравни с таблицей Наблюдаемые частоты на рис.15). Голубой цвет относится к женщинам, красный - к мужчинам. Видно, что высоты столбцов почти одинаковы, что и говорит об одинаковой встречаемости стенокардии в этих выборках, как это и показали статистические тесты, см.рис.16
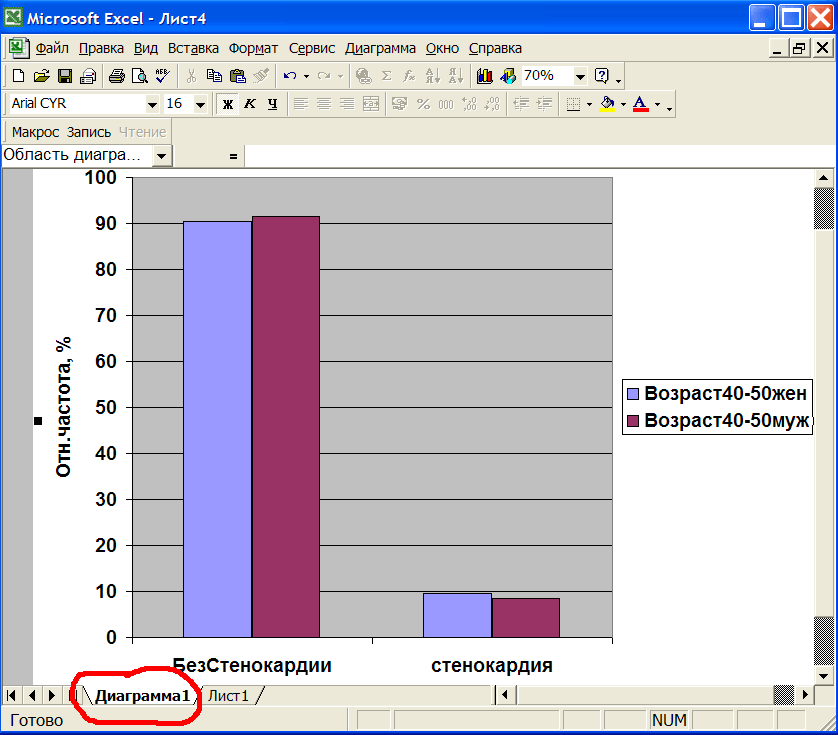
Рис.16 Гистограмма частот.
Количество выборок и/или количество условий сравнения может быть больше 2-х. В этом случае результаты критерия Фишера не выводятся, и выполняется только тест хи-квадрат.